生成AIを最大限活用するためには、生成AIのモデルの違いを把握することが大切です。
この記事では、テキスト生成AI・音声生成AI・動画生成AIに分けて、それぞれに用いられている生成AIモデルの種類と特徴を詳しく解説します。
プロライターも認める高品質。今ならトライアル無料
SEO記事からインタビュー原稿、PR、LP原稿制作まで。あらゆるプロの実務に対応するAIライティングアシスタント「Xaris(カリス)」。今なら無料トライアルをお試しいただけます。

1.AIと生成AIの違い
従来のAIと生成AIの違いは、アウトプットの種類にあります。従来のAIは、大量のデータから学習し、そのデータに基づいて「識別」や「予測」を行うのが得意でした。例えば、画像に何が写っているかを識別したり、過去のデータから未来の売上を予測したりするといったことです。
一方、生成AIは、学習データをもとに新しいコンテンツを「創造」することができます。テキスト、画像、音声、動画、コードなど、多様なアウトプットが可能です。従来のAIがデータに基づいて既存の情報を分析するのに対し、生成AIは新しい情報を生成するという点で大きく異なります。
従来のAIはデータ分析に特化しているのに対し、生成AIは創造性を発揮できる点が特徴です。この創造性は、ビジネスや日常生活のさまざまな場面で革新的な変化をもたらすと期待されています。
2.生成AIモデルとは
生成AIモデルとは、学習したデータに基づいて入力データを解析し、新しいコンテンツを創造するプログラムを指します。
生成AIモデルにはさまざまな種類があり、それぞれ得意なタスクや出力するデータの種類が異なります。生成AIの性格を決定づけるのが生成AIモデルと言っていいでしょう。
これらの生成AIモデルの違いを理解することによって、下記のようなメリットが得られます。
- 目的に応じたモデルを選択できる
- 生成AIの能力を最大限に引き出せる
- より高品質なアウトプットを得られる
- 新しいサービスを創出する手助けになる
生成AIモデルは日々進化しており、今後さらに多くの種類が登場すると予想されます。それぞれのモデルの特徴を理解し、目的に応じて適切に使い分けることで、ビジネスや日常生活のさまざまな場面で効率化やアイデア発見のサポートをしてくれるでしょう。
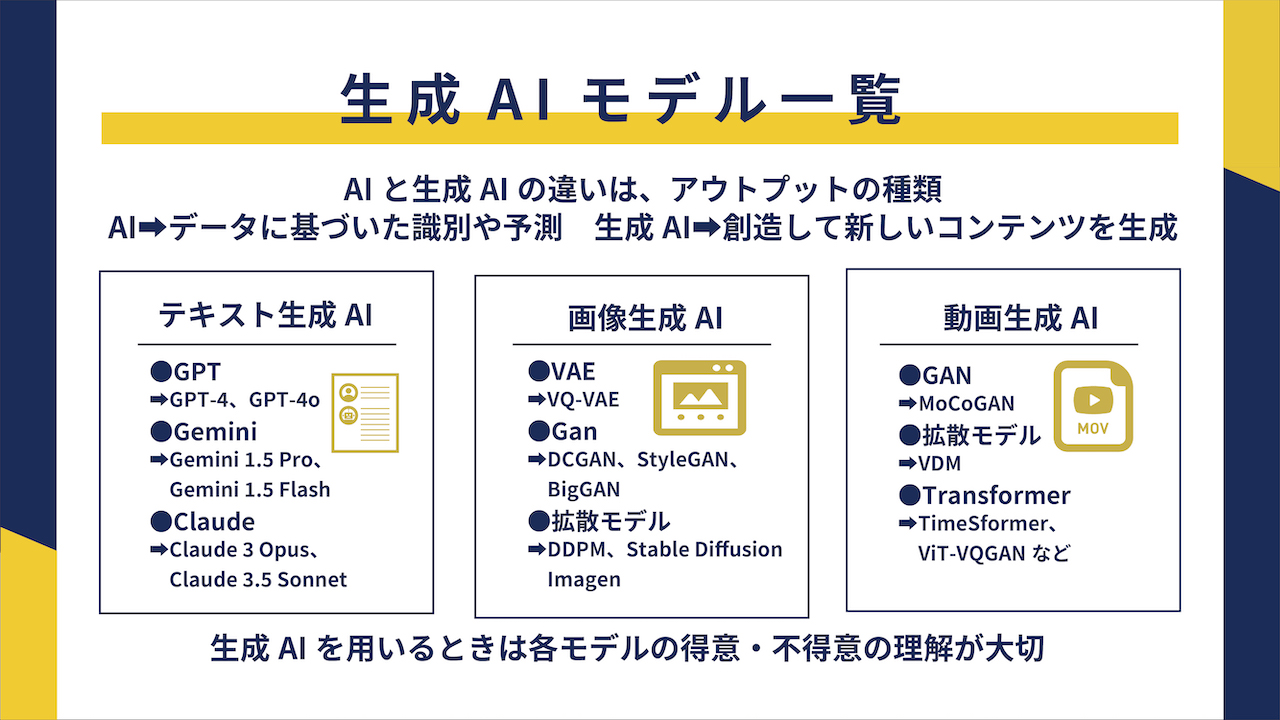
3.生成AIモデルの種類一覧
生成AIモデルは、生成AIの種類によっていくつかの種類に分けられます。テキストを扱うテキスト生成AI、画像を生成する画像生成AI、動画を生成する動画生成AI、それぞれに用いられている主要な生成AIモデルは以下のとおりです。
| 種類 | 主要モデル |
| テキスト生成AI | ・GPT(GPT-4、GPT-4oなど) ・Gemini(Gemini 1.5 Pro、Gemini 1.5 Flashなど) ・Claude(Claude 3 Opus、Claude 3.5 Sonnetなど) |
| 画像生成AI | ・VAE(VQ-VAE) ・GAN(DCGAN、StyleGAN、BigGANなど) ・拡散モデル(DDPM、Stable Diffusion、Imagenなど) |
| 動画生成AI | ・GAN(MoCoGAN、TGAN、VGANなど) ・拡散モデル(VDM、Video Generation from Textなど) ・Transformer(TimeSformer、ViT-VQGANなど) |
テキスト生成AIモデル
テキスト生成AIモデルは、大量のテキストデータを学習し、ユーザーの入力に基づいて新しいテキストを生成するAIモデルです。
| モデル名 | 特徴 |
| GPT | 自然言語処理に特化 |
| Gemini | テキスト、画像、音声などのデータを同時に扱えるネイティブマルチモーダル |
| Claude | 読み込める文章量が多く、コード生成能力が高い |
これらのモデルは、それぞれ異なるアーキテクチャや学習データを用いており、得意とするタスクも異なります。
GPTは、例えばビジネスメールの作成などの基本的な業務から、企画のアイデア出しまで、多岐にわたる業務で活用可能です。Geminiでは、日常的なアイディア出しや壁打ち、コード生成などに活用されており、ネイティブマルチモーダルの特徴を活かしています。Claudeは、LP制作や大量の手書き資料のスライド化に活用されています。
これらのモデルは日々進化しており、精度の向上や新たな機能の追加が期待されています。ユーザーは自身の目的に最適なモデルを選択し、活用することで、さまざまなタスクを効率的に遂行できます。
画像生成モデル
画像生成モデルはAIを使って新しい画像を作り出す技術です。具体的な例として、実在しない人物の顔写真や、特定の画風のイラストなどを自動で生成できます。
この技術は、大量の画像データを学習することで、画像の特徴やパターンをAIが理解し、それらを元に新しい画像を生成することを可能にしています。
画像生成モデルの中でも、特に有名なのが「VAE」「GAN(敵対的生成ネットワーク)」「拡散モデル」などです。
| モデル名 | 特徴 |
| VAE | データから自動的に特徴を学習する能力と潜在空間(モデルがデータの本質的な部分を捉えている空間)をスムーズに構築する能力がある |
| GAN(敵対的生成ネットワーク) | 2種類の機械学習モデル(生成モデルと識別モデル)を競い合わせ、出力データの精度を自動的に高める技術を採用。これにより、リアルで高品質な画像を生成する |
| 拡散モデル | 元々の画像を徐々にノイズ化していき、逆にそのノイズを取り除くことで画像を生成するという逆過程を学習する |
これらのモデルは、エンターテイメント、広告、デザインなど、さまざまな分野で活用されています。例えば、ゲームのキャラクターデザイン、広告バナーの作成、アーティストの創作活動支援などが挙げられます。
動画生成モデル
動画生成モデルは、静止画から動画への変換、テキストから動画への変換、あるいは既存動画の編集や変換など、多様なタスクをこなします。エンターテイメント、教育、広告など幅広い分野での活用が期待されています。
動画生成AIは、主にGAN、拡散モデル、Transformerをベースに開発されています。
| モデル名 | 特徴 |
| GAN | 時系列の情報処理に特化したものや、コンテンツの安定性を高めたものなどバリエーションが豊富 |
| 拡散モデル | 時間的整合性を考慮しながら高品質な動画を生成 |
| Transformer | 滑らかな動きや一貫性のある動画を生成するのに最適 |
動画生成AIを活用することで、高品質な動画を効率的に制作できます。例えば、商品やサービスの魅力をアピールするプロモーション動画の作成や、ターゲットに合わせた動画広告を臨機応変に作成することが可能です。
一方で、フェイク動画の流通や著作権侵害などのリスクへの対策は欠かせません。意図せずとも著作権侵害になってしまうケースも考えられるため、健全な利用ルールの整備が重要な課題となるでしょう。リスク対策が整えば、動画生成AIのビジネス活用はますます広がっていくことが期待できます。
4. テキスト生成AIモデルごとの違い
ここでは、AIライティングアシスタントツールのXarisを使用して、代表的なテキスト生成AIモデルの違いをご紹介します。
テキスト生成AIモデルごとの出力文章の違い
実際にGPT-4o、Gemini 1.5 Pro、Claude 3.5 Sonnetの3つのモデルの出力文章を比較してみましょう。
今回は、下記のプロンプトで違いを比較します。
| 以下の条件に基づき、生成AIについて解説するメディア記事の文章を作成してください。 ■条件・400文字程度・「です」「ます」調・2~3行ごとに改行をする・メリットとデメリットを併記 |
GPT-4o
GPT-4oの出力結果は下記の通りです。

まず、プロンプトから何について解説すべきかを理解し、「生成AIのメリットとデメリット」という見出しを作成している点から、自然言語処理能力が高いことがわかります。
全体的に文法やスタイルが整っており、読みやすい印象を受けるでしょう。
後述のGeminiとClaudeと異なる点は、文章が論理的で段階的に説明されている点です。全体を通して、「〜〜ため、〜〜ます。」という文章が出力されており、詳細で丁寧な解説がされています。
Gemini 1.5 Pro
Gemini 1.5 Proの出力結果は下記の通りです。

GPT-4oでは「生成された情報が誤っている場合や偏った内容を含む場合があり」と表現している部分が、Gemini 1.5 Proでは、「AIが生成した情報が必ずしも正確とは限らないため」と表現されています。
これはGeminiが情報提供において、精度を重視し冗長性を避けてポイントを押さえた出力をしていることがわかります。
また、後述のClaudeが出力した生成AIの説明部分と比べてみても、Geminiは必要な情報を簡潔に提供しています。
Claude 3.5 Sonnet
Claude 3.5 Sonnetの出力結果は下記の通りです。

「様々な文書作成をサポートしてくれるのです。」という言い回しが、ユーザーに寄り添うようなトーンで書かれているように感じ取れます。
また、GPT-4oでは「労力を大幅に削減」と表現されていた部分が「文書作成の時間を大幅に短縮」という表現になっており、全体的に複雑な表現を避けている印象を受けます。
テキスト生成AIモデルごとの取得する情報の違い
テキスト生成AIは、大量のテキストデータを学習することで、多様な文章を生成できます。しかし、学習データの種類や範囲、モデルの設計思想によって、得意な分野や不得意な分野、出力の精度に差が生じます。
| モデル | 得意分野 | 不得意分野 | 情報の鮮度 |
| GPT-4o | 論理的思考、推論、文章生成、翻訳、コード生成 | 最新の情報、複雑な視覚的推論 | 2023年10月までのWeb上の情報や専門的なデータベースから取得(それ以降の情報はWeb検索で取得) |
| Gemini 1.5 Pro | 複雑な推論、マルチモーダル理解、創造的なコンテンツ生成、コード生成 | 専門知識の深さ、倫理的な問題 | Googleの膨大な知識グラフおよび検索データを含む広範なデータから取得 |
| Claude 3.5 Sonnet | 会話、文章生成、要約、翻訳 | 複雑な計算、コード生成 | 2024年4月までのWeb上の情報や論文などの膨大なテキストデータを保持 |
GPT-4oは、論理的思考や推論、文章生成、翻訳、コード生成などが得意です。2023年10月時点までの下記データを収集し学習しています。
- インターネット上の公開情報(Webページ、ブログなど)
- 書籍(学術論文や教科書など)
- 公開データセット(Wikipediaなど)
- 専門的なデータベース(科学論文のアーカイブや法律文書のデータベースなど)
2023年11月以降の情報はWeb検索での取得元に依存します。つまり、2023年10月までの学習データと比べると取得する情報が制限されるため、複数の信頼できる情報源と照らし合わせて慎重に検証することが重要です。
Gemini 1.5 Proは、複雑な推論、マルチモーダル理解に基づく創造的なコンテンツ生成、コード生成などを得意としています。テキスト情報だけでなく、画像や音声、動画から情報も取得できます。しかし、専門知識の深さや倫理的な問題については、まだ発展途上です。
Claude 3.5 Sonnetは、会話、文章生成、要約、翻訳などを得意としています。一方、複雑な計算やコード生成は苦手です。
このように、テキスト生成AIモデルによって取得できる情報の種類や鮮度は大きく異なります。加えて、同じモデルでもバージョンが異なれば、学習データの範囲やモデルの設計が異なるため、出力結果に違いが生じることがあります。
5. 画像生成AIモデルごとの違い
画像生成AIモデルにはさまざまな種類があり、それぞれ出力画像の特徴や、学習に用いる情報が異なります。ここではStyleGANとDDPMを比較し、それぞれの特徴を見ていきましょう。
StyleGANは、GANの一種で、高解像度で写実的な画像の生成に特化しています。StyleGANは、画像の潜在空間(モデルがデータの本質的な部分を捉えている空間)を操作し、生成される画像の特徴を細かく制御できることも特徴です。
DDPM(Denoising Diffusion Probabilistic Models)は、拡散モデルの一種であり、ノイズ除去プロセスを通じて画像を生成します。DDPMは、StyleGANに比べて計算コストが高く、生成速度が遅いという欠点がありますが、多様な画像を生成でき、画像の品質も高いという利点があります。
6. 動画生成AIモデルごとの違い
動画生成AIモデルは、静止画を連続的に生成することで動画を作成します。動画生成AIモデルごとに得意な動画の種類や生成方法が異なります。ここでは、MoCoGANとTimeSformerの違いを解説します。
MoCoGANは、GANをベースとした動画生成AIモデルです。MoCoGANは、動画を動きの情報(モーション)と見た目(コンテンツ)の情報に分けて学習します。これにより、動きの滑らかな動画を生成できます。MoCoGANは、主に短い動画の生成に使用されています。
TimeSformerは、Transformerをベースとした動画生成AIモデルです。TimeSformerは、動画を時系列データとして捉え、長時間の動画でも高精度に生成できます。TimeSformerは、主に長時間の動画の生成に使用されています。
7. ビジネスにおける生成AIの活用シーン
生成AIはさまざまなビジネスシーンで活用され、業務効率化や新しい価値の創出に貢献しています。ここでは、具体的な活用シーンをいくつかご紹介します。
テキスト生成AI:データ抽出
テキスト生成AIは、大量のテキストデータから必要な情報を効率的に抽出するのに役立ちます。例えば、顧客からのフィードバックを分析する場合、大量のフィードバックの中から特定の製品に関する意見や顧客が抱える問題点などを自動的に抽出可能です。
データ抽出の手間を大幅に削減し、ビジネスにおける意思決定を迅速化するのに役立ちます。
テキスト生成AI:文章の要約
テキスト生成AIは文章の要約にも役立ちます。大量のテキストデータから学習した高度な言語理解能力と豊富な知識を活かして、より自然で正確な要約を生成可能です。例えば、以下のようなニュース記事を要約する場合を考えてみましょう。
| A社は新製品Xを開発し、市場に投入すると発表した。Xは従来製品より性能が向上しており、価格も抑えられている。A社はXによって市場シェア拡大を狙っている。 |
テキスト生成AIを用いて要約してみると、下記のように要約します(モデルはGemini 1.5 Proを使用)。
| A社は、性能と価格のバランスに優れた新製品Xを投入し、市場シェア拡大を目指します。 |
このようにテキスト生成AIは、単に情報を圧縮するだけでなく、重要な情報を抽出し、人間が理解しやすい形で提示できます。これは、議事録作成、ニュース記事の要約、論文の抄録作成など、さまざまな場面で役立ちます。
テキスト生成AI:キャッチコピー作成
キャッチコピー作成もテキスト生成AIを活用できます。商品の特徴やターゲット層、市場のトレンドなどをAIに学習させることで、効果的なキャッチコピーの候補を生成可能です。
具体的には、以下のような手順でキャッチコピーを作成できます。
- 商品の特徴やターゲット層、競合製品などに関する情報をAIにインプット
- 生成AIが複数のキャッチコピー候補を生成
- 生成されたキャッチコピー候補の中から、最適なものを選定
- 必要に応じて、選定したキャッチコピーを修正・調整
テキスト生成AIを活用することで、キャッチコピー作成にかかる時間と労力を大幅に削減できます。また、人間の発想にとらわれない、斬新なキャッチコピーが生まれる可能性もあります。しかし、テキスト生成AIはあくまでもツールであるため、最終的な判断は人間が行う必要があります。
生成されたキャッチコピーをそのまま使用するのではなく、人間の知見や感性を加えることで、より効果的なキャッチコピーを作成することが重要です。
テキスト生成AI:プログラミングのコード生成
テキスト生成AIは、プログラミングのコード生成にも活用できます。開発時間の短縮やバグ修正、リファクタリングといった作業にも役立つでしょう。
テキスト生成AI:音声の文字起こし
音声認識技術を組み込んだ生成AIモデルは、音声をリアルタイムで文字起こしすることが可能です。会議の議事録作成やインタビュー記事の作成、動画コンテンツの字幕作成などに活用できます。
画像生成AI:商品開発やデザイン
画像生成AIは、商品開発やデザイン作成において業務効率化やアイデア創出に役立ちます。例えば、既存商品の画像をAIに学習させ、デザインの改善点を提案させたりバリエーションを自動生成させたりできます。
画像生成AIを使えば、顧客のニーズに合わせた商品改良を迅速に実施でき、市場競争力を高められます。
動画生成AI:臨機応変なプロモーション動画作成
動画生成AIを活用すれば、ターゲット層に合わせたプロモーション動画を臨機応変に作成できます。
例えば、新商品の発売やキャンペーンに合わせて、プロモーション動画を作成・配信することが可能です。また、ターゲット層に合わせた動画のパーソナライズも容易に行えます。
変化の激しい現代において、臨機応変なプロモーション活動は不可欠です。動画生成AIを活用すれば、競争優位性を築き、ビジネスの成長を加速させることができるでしょう。
8.生成AIモデルの違いを理解して最大限に活用しよう
生成AIモデルはたくさん登場しており、モデルの違いを理解することで生成AIを最大限に活用できます。
このような特徴を知ると、場合によってはモデルを使い分けたいシーンも出てくるでしょう。特にテキスト生成は、それぞれ使い分けられるとより効率化につながります。
ただ、テキスト生成AIの場合、ツールごとに使用できるモデルが1つであることが一般的で、使用したいモデルによってツールを使い分ける必要があります。
そこでおすすめしたいのが、ライティングアシスタントツールのXarisです。Xarisは、GPT・Gemini・Claudeという3つのモデルを搭載しており、切り替えが簡単に行えます。そのため、さまざまなシーンに合わせて活用することが可能です。もし、テキスト生成AIツールを導入したいと考えている場合は、無料トライアルで試してみるのがおすすめです。